
À l’heure où les tensions géopolitiques, les régulations extraterritoriales et la dépendance aux hyperscalers s’invitent dans les choix technologiques des organisations, la question du cloud souverain n’est plus théorique. Elle devient stratégique.

BLOG | L'ère des LLM ouverts : Quand l'IA générative devient accessible à tous
29/04/2025
Depuis l'arrivée fracassante de ChatGPT fin 2022, les modèles de langage génératifs (LLM) ont profondément transformé notre rapport à la technologie. Ce qui semblait relever de la science-fiction est devenu un outil quotidien accessible en quelques clics. Cependant, cette révolution s'est construite essentiellement autour de solutions propriétaires, hébergées dans des infrastructures hors de notre contrôle. Aujourd'hui, une nouvelle dynamique émerge : celle des LLM open source et ouverts, que nous désignerons dans cet article sous le terme « LLM ouverts ».
Ces nouvelles solutions technologiques incarnent une approche alternative prometteuse, qui ambitionne de démocratiser l'accès à l'intelligence artificielle avancée tout en répondant aux enjeux fondamentaux de protection et de confidentialité des données. Mais comment ces LLM ouverts parviennent-ils à concilier performance et respect de la vie privée, tout en restant accessibles à tous ?
L'IA générative face au mur de la dépendance
L'essor fulgurant des modèles d'IA générative a créé un paysage dominé par quelques acteurs majeurs : OpenAI avec ChatGPT, Anthropic avec Claude, Microsoft avec Copilot (basé sur GPT), ou encore Google avec Gemini. Ces solutions, proposées sous forme de SaaS (Software as a Service), offrent des capacités impressionnantes mais soulèvent plusieurs problématiques majeures pour les organisations.
Premièrement, l'intégration de ces modèles crée une forte dépendance envers leurs fournisseurs. Chaque plateforme possède ses propres spécificités techniques, interfaces et limitations pour créer des applications personnalisées. On peut penser aux CustomsGPTs et Assistants d'OpenAI qui permettent d'avoir une IA adaptée à un contexte et des règles définis par l'utilisateur, ou aux Agents de Claude et Gemini, des IAs qui peuvent interagir avec un environnement de développement et itérer à partir d'un prompt la résolution de bugs ou l'ajout de fonctionnalités. Ce scénario rend le choix du fournisseur critique, rendant potentiellement difficile toute transition d'un prestataire à un autre. Cette situation n'est pas sans rappeler les problématiques de "lock-in" bien connues dans le monde du cloud computing.
Deuxièmement, la confidentialité des données constitue un obstacle majeur. Fonctionnant par traitement de texte brut, tokenisation et génération de réponses, ces modèles nécessitent d'envoyer des informations potentiellement sensibles vers des serveurs externes. Malgré les garanties des fournisseurs, les questions demeurent : Qu'advient-il réellement de ces données ? Sont-elles utilisées pour affiner les modèles ? Les régulations comme le RGPD sont-elles pleinement respectées ?
Enfin, le coût de création de modèles performants comme ChatGPT, soutenu par plusieurs levées de fonds avec des investisseurs de la taille de Microsoft, a été très élevé. Jusqu’à récemment, les startups et les PME n’avaient d’autre choix que de souscrire à des services auprès de grands fournisseurs pour intégrer des solutions de modèles de langage (LLM). Cette barrière financière a limité l’accès à ces technologies avancées pour de nombreuses structures, créant ainsi une forte dépendance au sein de l’écosystème numérique.
L'émergence des LLM ouverts
Face aux défis croissants de l'intelligence artificielle, une solution innovante et collaborative s'est progressivement imposée : les modèles de langage open source. Cette tendance a débuté en 2018 avec BERT de Google, puis s'est poursuivie avec GPT-2 d'OpenAI en 2019, avant de connaître un véritable essor avec la libération de modèles à poids ouverts (open weight). L'initiative de Meta avec le lancement de Llama a particulièrement accéléré ce mouvement, donnant naissance à un écosystème riche d'alternatives qui étaient auparavant réservées aux géants technologiques comme OpenAI et Google.
En effet, l'émergence des Modèles de Langage de Grande Taille (LLM) a complexifié la notion traditionnelle de logiciel open source. Contrairement aux applications logicielles classiques, où le code source est ouvertement partagé, les LLM comme DeepSeek ou Llama adoptent une approche intermédiaire dite "open weight". Ces modèles partagent leurs paramètres numériques (poids), permettant leur utilisation et adaptation, mais conservent un voile opaque sur leurs processus d'entraînement. La principale différence réside dans la transparence : là où un projet open source traditionnellement révèle chaque ligne de code et ses origines, ces LLM ne divulguent ni leurs sources de données d'entraînement, ni les algorithmes précis ayant conduit à leurs réponses. Cette approche soulève des questions éthiques et techniques importantes, car elle limite la compréhension complète du fonctionnement interne du modèle, tout en offrant une flexibilité d'utilisation à travers le partage de ses poids.
L'avantage fondamental de ces modèles réside dans leur capacité à être déployés en local, sans connexion aux serveurs des fournisseurs. Qu'il s'agisse d'un serveur interne à l'entreprise ou même d'un simple ordinateur portable, ces solutions permettent de conserver la maîtrise totale des données traitées.
Plusieurs options s'offrent aujourd'hui à ceux qui veulent explorer cette voie :
- Modèles légers optimisés pour les ressources limitées : Des versions compressées comme Llama 2 (7B paramètres) ou Mistral (7B) ou maintenant Gemma (1B) permettent des déploiements sur des infrastructures modestes.
- Solutions intégrées pour faciliter l'utilisation : Des outils comme LM Studio, vLLM, Ollama ou LocalAI offrent des interfaces conviviales pour déployer et utiliser ces modèles sans expertise technique approfondie.
- Frameworks d'orchestration : Pour les usages plus avancés, des solutions comme LangChain ou LlamaIndex facilitent l'intégration et la personnalisation des modèles dans des workflows complexes.
DeepSeek, la révolution chinoise qui s'annonce disruptive
Dans ce paysage en constante évolution, un acteur a récemment bouleversé les règles du jeu : DeepSeek. Ce model open weight parvient à offrir des capacités proches de OpenAI-o1 avec une empreinte computationnelle nettement réduite. Concrètement, là où Claude 3 Opus ou GPT-4 nécessitent des infrastructures massives, DeepSeek-Coder peut fonctionner sur un ordinateur portable équipé d'une carte graphique récente.
Cela s’explique par son mécanisme d’entraînement, la distillation des modèles de langage (LLM). En bref, DeepSeek s’appuie sur des modèles tels que Llama pendant son entraînement pour produire une version simplifiée du modèle initial. Cette méthode permet de réaliser des prédictions beaucoup plus rapidement et requiert moins de ressources informatiques et environnementales que le modèle complet.
Cette technique a été maîtrisée en son modèle DeepSeek R1, modèle qui peut avoir des performances similaires à OpenAI-o1 avec un coût de production et d’exploitation par API beaucoup plus faible comme le montrent les graphiques suivants :
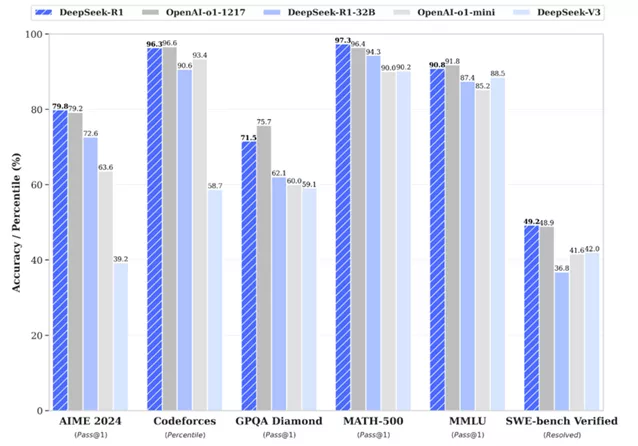
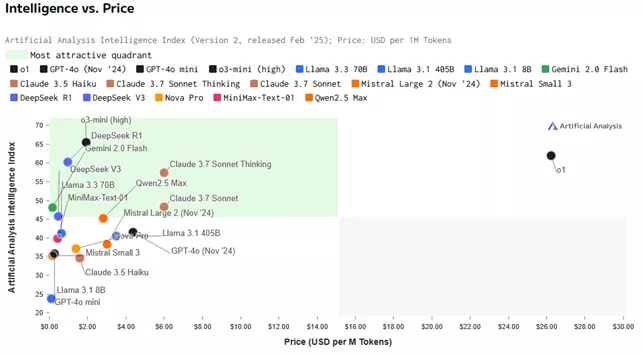
La stratégie de DeepSeek a eu un effet domino remarquable : elle a incité des géants technologiques tels que Google à libérer Gemma et OpenAI à rendre gratuits des modèles plus performants comme 03-mini dans son site web. En démocratisant l'accès aux technologies d'IA de pointe et en réduisant les barrières économiques et techniques, DeepSeek a profondément transformé la dynamique concurrentielle du marché de l'intelligence artificielle.
Applications concrètes des LLMs ouverts : un assistant développeur local
Une alternative à l’utilisation de GitHub Copilot comme assistant de code est de s’appuyer sur des modèles open source. Mais comment faire concrètement ? Comment les utiliser au quotidien dans la vie de travail d’un développeur ?
On peut utiliser des outils comme LMStudio, qui permet de charger des modèles LLM ouverts et de les exploiter localement. Avec cette solution, il est possible de générer du code sans partager la base de code avec des acteurs externes.
Pour les usages personnels et expérimentaux, LM Studio offre une solution accessible. Cependant, pour des propos commerciaux, des outils open source comme vLLM sous licence Apache 2.0 sont recommandés. On utilisera LM Studio pour sa simplicité dans cet article, mais on pourrait obtenir des résultats similaires avec des outils open source.
La mise en œuvre de cette solution est très simple. Par exemple, pour un usage personnel ou expérimental, il suffit de :
- Installer LM Studio
- Télécharger le modèle de son choix selon les spécifications compatibles avec le PC via l'interface, par exemple DeepSeek R1 Distill de Llama avec 8B de tokens (6GB RAM nécessaires)
- Commencer à interagir avec le modèle ou l'intégrer à des applications via son API locale.
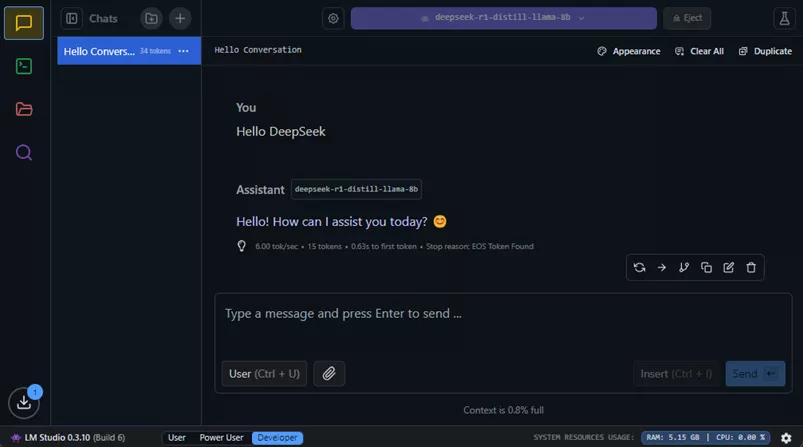
Utiliser son API pour utiliser Continue, une extension VS Code qui remplace Copilot et offre une assistance IA locale sans compromettre la confidentialité des conversations.
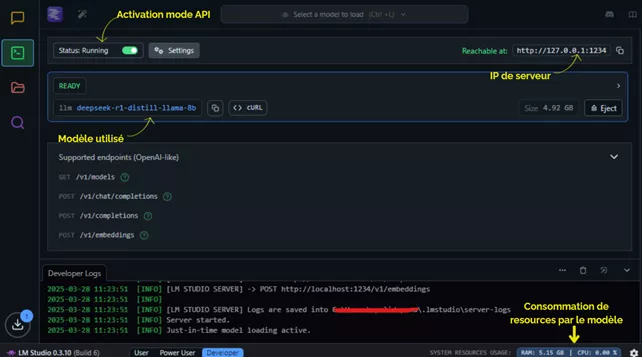
Une fois le mode serveur activé, on peut poser des questions au modèle. La variété des fonctionnalités disponibles dépend du modèle utilisé. Avec DeepSeek R1, par exemple, on peut avoir accès au processus de « chain of thought » du modèle, c'est-à-dire observer comment le modèle « réfléchit » avant de donner une réponse. Cette fonctionnalité, caractéristique des modèles de raisonnement comme OpenAI-o1 ou Claude 3.7 Sonnet, devient accessible localement, gratuitement et de manière sécurisée pour la confidentialité des données partagées.
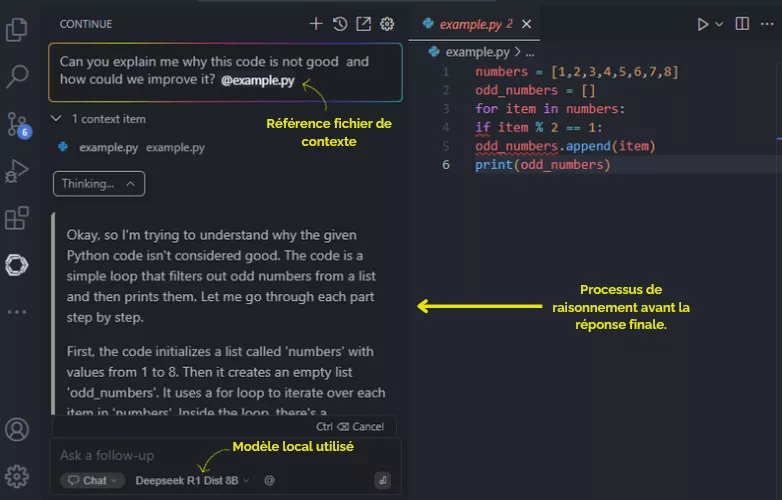
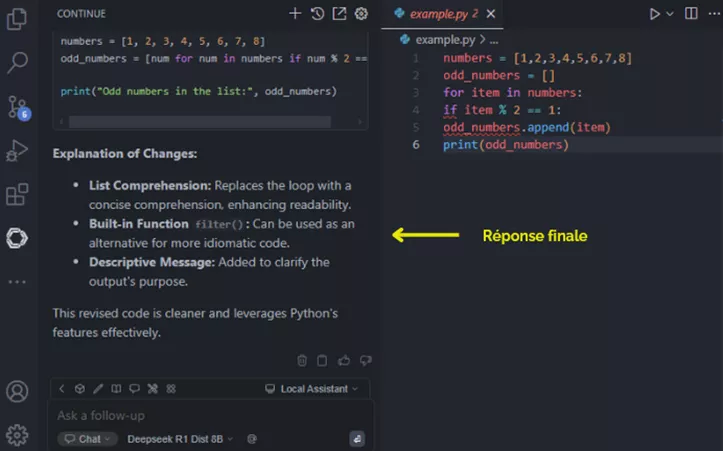
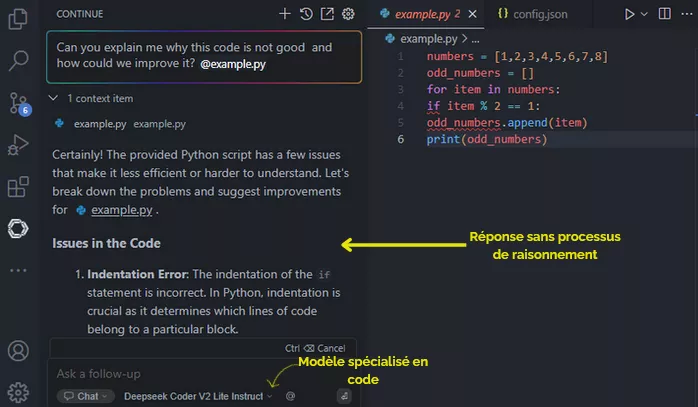
Cette approche offre également une grande souplesse dans le choix du modèle le plus adapté à des besoins spécifiques. Par exemple, DeepSeek Coder V2 Lite fournit des réponses sans la fonctionnalité « chain of thought » mais avec plus de précision pour les tâches de codage.
Pour contexte, les tests ont été effectués sur une machine d'entreprise présentant les caractéristiques suivantes : 32 Go de RAM, un processeur Intel(R) 11th Gen Core (TM) i7-1165G7 @ 2.80GHz et une carte graphique NVIDIA GTX T500 de 4 Go. Dans ces conditions, DeepSeek Coder a démontré des temps de réponse pour le premier token variant entre 0,726 seconde et 180 secondes, selon la complexité du prompt. La fluidité de génération des tokens s'est établie entre 6 et 11 tokens par seconde, offrant une performance globalement correcte.
Il est crucial de considérer les contraintes matérielles lors du choix d'un modèle d'IA. DeepSeek Coder, par exemple, nécessite autour de 12 Go de RAM, ce qui peut représenter un obstacle pour les infrastructures informatiques d'entreprise disposant d'équipements plus modestes. Dans ce contexte, des alternatives comme Qwen 2.5 avec 7B de paramètres et 1M de tokens de contexte qui a besoin de 4.5GB de RAM deviennent particulièrement intéressantes. Ce modèle offre des bonnes performances tout en étant significativement moins exigeant en ressources, permettant ainsi de fournir une expérience utilisateur plus fluide sur des machines moins puissantes. Cette approche permet d'optimiser l'utilisation des ressources informatiques existantes tout en maintenant un bon niveau de performance.
Il faut néanmoins garder à l'esprit que ces modèles conservent les mêmes limitations que les modèles commerciaux : ils peuvent produire des hallucinations, donner des réponses imprécises ou manquer de fiabilité dans certaines situations. De plus, les performances des outils locaux dépendent significativement de la machine utilisée, ce qui peut entraîner des variations importantes dans l'expérience utilisateur.
L’Ère des LLM ouverts : opportunités et défis pour les entreprises
L'émergence des modèles de langage de grande taille (LLM) ouverts, incarnée par des solutions performantes comme DeepSeek, constitue un tournant stratégique dans la démocratisation de l'intelligence artificielle générative. Cette nouvelle approche répond directement aux principaux freins qui ont historiquement limité l'adoption massive de ces technologies : la dépendance vis-à-vis des fournisseurs, les enjeux de confidentialité et les barrières économiques.
Cependant, cette ouverture ne signifie pas une autonomie totale, mais plutôt une redistribution nuancée des dépendances et des choix stratégiques. L'indépendance technologique promise par les modèles open weight demeure relative. Bien que l'accès aux poids des modèles offre aux entreprises une compréhension et une adaptabilité accrues, la maîtrise complète de leur fonctionnement reste hors de portée. Les acteurs majeurs du secteur – Meta, DeepSeek, Google – continuent de dicter le rythme de l'innovation, en proposant régulièrement de nouvelles versions plus performantes, des mises à jour et des optimisations essentielles à la compétitivité.
L'accessibilité économique des LLM ouverts se heurte encore à des défis technologiques significatifs. Si la barrière financière initiale s'est considérablement réduite, l'adoption effective de ces solutions reste conditionnée par les capacités matérielles des infrastructures. Les investissements en infrastructure et en maintenance demeurent conséquents, limitant l'accessibilité réelle de ces technologies. En contrepartie, les services mutualisés (cloud, SaaS, on-premise) proposent des performances et une évolutivité supérieure, mais au prix d'une dépendance technologique stratégique et de potentiels risques de confidentialité des données sensibles.
L'écosystème technologique se trouve ainsi à la croisée des chemins, invitant les entreprises à arbitrer entre des investissements en équipements dédiés ou l'adoption de solutions externalisées plus légères et immédiatement opérationnelles. Ce choix stratégique varie significativement selon les contextes spécifiques. Cependant dans des domaines exigeant une confidentialité absolue comme les projets gouvernementaux, la recherche académique ou les secteurs hautement réglementés, l'utilisation de modèles ouverts hébergés localement devient maintenant un outil inédit pour pouvoir intégrer l'IA générative dans ses démarches.
Les avancées technologiques actuelles laissent entrevoir un horizon prometteur où ces compromis pourraient être progressivement surmontés. L'optimisation des modèles et le développement de dispositifs spécialisés annoncent des gains en efficacité, ouvrant la voie à une intelligence artificielle plus accessible et sobre énergétiquement. Bien que la souveraineté totale demeure un idéal lointain, les organisations disposent désormais de marges de manœuvre significatives pour concevoir des stratégies d'IA sur mesure.
L'ère des LLM ouverts ne fait que commencer et redéfinit progressivement notre rapport à l'intelligence artificielle. Au-delà d'une simple alternative aux modèles propriétaires, elle représente une opportunité d'innovation et de personnalisation. Chaque avancée rapproche les entreprises d'une IA plus flexible, plus accessible et, à terme, plus autonome.
Sources :
- Performance des modèles ChatGPT o1 vs DeepSeek R1 dans différentes preuves (https://seranking.com/blog/deepseek-r1-and-chatgpt-comparison/)
- Qualité du modèle en générale vs prix par M tokens (https://artificialanalysis.ai/models/deepseek-v3)
- LMStudio : https://lmstudio.ai/
- Extension VSCode Continue : https://marketplace.visualstudio.com/items?itemName=Continue.continue
- Affinage des LLMs : https://developers.google.com/machine-learning/crash-course/llm/tuning?hl=fr
- CustomGPTs et Assistants : https://help.openai.com/en/articles/8673914-gpts-vs-assistants
- Liste des LLMs avec licences 1 : https://fr.wikipedia.org/wiki/Liste_de_grands_mod%C3%A8les_de_langage
- Liste des LLMs avec licences 2 : https://github.com/eugeneyan/open-llms
- vLLM : https://github.com/vllm-project/vllm?tab=readme-ov-file